Für eine effektvolle und reibungslose Arbeit mit Git sind die Kenntnisse der Kommandos selbst nicht ausreichend. Die kann man übrigens jederzeit in Dokumenten finden - hier ist vor allem das Verständnis der Philosophie dieses riesigen Tools erforderlich. Also am Anfang ein paar nützliche theoretische Informationen.
Was ist eigentlich Git und wie speichert Git die Daten
Einfach gesagt, Git ist eine Datenbank, die die einzelnen Versionen des Projektes in folgenden Arbeitsphasen speichert. Git speichert nicht Unterschiede zwischen den Dateien – sondern Schnappschüsse (eng. Snapshot) des gesamten Projektes. Dieser Snapshop heißt Commit oder Revision und wird über die eigene SHA1-Prüfsumme identifiziert. Die Kommandos von Git operieren gewöhnlich mehr oder weniger offensichtlich mit Revisionen: durchs Vergleichen, Zusammenführen und Synchronisieren mit dem Arbeitsverzeichnis usw.
Historie der Änderungen, Zweige
Jeder Commit enthält einen Verweis auf seinen Vorgänger, das heißt dass der Satz der aufeinanderfolgenden Revisionen eine Kette bildet. Damit kann die gesamte Historie der Änderungen in Git strukturiert werden.
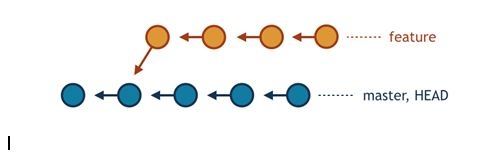
Das obige Muster präsentiert die Historie der Änderungen mit zwei parallelen Commit Ketten und drei Branches. Die Revisions-Kette bildet einen Zweig, wenn sich ein genannter Branch auf ein Element der Kette bezieht (hier feature oder master). Die Kette ist ein aktiver Zweig, wenn auf dieses Element zusätzlich HEAD verweist – dann ist das Arbeitsverzeichnis mit der dem Branch zugeschriebenen Revision synchronisiert (d.h. alle Änderungen in Dateien werden in Bezug auf die Revision gefolgt).
Bestimmung der Revision und der Revisionsbereiche
Während der Arbeit mit Git können Sie auf Revisionen auf unterschiedliche Art verweisen:
- direkt durch SHA-1 (z.B. f8519fd29909ed37b1e83fad6f259d3e6ed9a9ae)
- direkt durch Abkürzung SHA-1 (z.B. 6bc603b), soweit sie eindeutig ist
- durch den Branch HEAD und die Branches für die Zweige (z.B: master, origin/master)
- relativ auf die Branches (z.B. HEAD^, HEAD~3, master~1)
- mit Verweis auf die früheren Zustände der Branches (HEAD@{3}, master@{yesterday}, master@{<date>})
- und durch Bereiche (master..HEAD, origin/master..master, feature...master)
Modifizierung der Änderungshistorie
Während der Arbeit mit umfangreichen Funktionalitäten erscheint das Problem der Kontrolle des bisher gespeicherten Codes: es ist ganz einfach, den roten Faden in den eingeführten Änderungen zu verlieren, etwas versehentlich zu überschreiben oder zu löschen. Eine Lösung hier sind häufige Commits, selbst von kleinen Änderungen – solche „partielle” Commits können als perfekte Sicherungspunkte gelten, wenn etwas schief geht.
Es muss noch bemerkt werden, dass der wichtigste Vorteil von Git, im Vergleich zu zentralisierten Versionskontrollsystemen, ist, mit privaten Zweigen lokal arbeiten und die Historie der eingeführten Änderungen beliebig modifizieren zu können – solange diese nicht in das offizielle Repository gepusht werden. Nachstehend ein Beispiel für die Historie der Änderungen in einem lokalen Zweig:
6bc603b (HEAD, feature) Uff, gut gemacht, fertig
.......
19d2cfb Vielleicht komme ich daraus zuruck
6f1f883 Mittagspause
08a1ae9 Ich errinnere mich nicht, was ich hier gemacht habe, aber es funktioniert
2df19e6 kleine Korrektur
b383b04 Ich habe die Funktion hinzugefuegt
fed82d9 Ich ueberschreib etwas Code
227c2c7 (origin/master) Some stable feature on master
Es ist ersichtlich, dass die Arbeit in den einzelnen Phasen mit einem ziemlich lockeren Stil beschrieben wurde, der nicht unbedingt für das offizielle Repository geeignet ist. Nehmen wir auch an, dass die Vereinbarungen des Teams verlangen, die gesamte Funktionalität mit möglichst wenigen Commits in Englisch zu bedienen. Hier kann das Rebase-Kommando mit der Option Interactive behilflich sein:
$ git rebase --interactive master
In diesem Fall ermöglicht das Kommando, die gesamte Historie abzuschreiben, beginnend mit der Stelle im master-Zweig von der der Zweig feature ausgeführt wurde (Verweis auf eine andere beliebige Revision dieses Zweiges auch möglich). Das interaktive rebase ermöglicht solche Operationen wie Zusammenführung von Commits, Änderung deren Reihenfolge, Bearbeitung der Beschreibungen und Ähnliches. Nach der Modifizierung kann die Historie folgend aussehen:
6bc603b (HEAD, feature) [FEATURE] Stable feature foobar
fed82d9 [MODIFICATION] Refactored classes foo and bar
227c2c7 (origin/master) Some stable feature on master
Der Zweig feature in der aktuellen Form kann mit dem Zweig master integriert und in dem offiziellen Repository gemeldet werden.
Anwendung des Codes eines anderen Zweiges
Nehmen wir an, dass der Zweig feature, aus welchen Gründen auch immer, nicht integriert werden konnte, wir möchten aber, dass sich das ausgeführte Refactoring der Klassen foo und bar (d.h. commit fed82d9) im Master befindet. Hier kommt uns das Kommando:
$ git cherry-pick fed82d9 zur Hilfe,
das das gegebene commit in den Zweig Master appliziert. Was aber, wenn wir Änderungen ausschließlich aus einer Datei verwenden möchten? Hier können wir das Kommando Checkout anwenden:
$ git checkout fed82d9 -- classes/bar.class
Die Datei bar.class wurde in Staging Area gespeichert und wird in dem nächsten Commit berücksichtigt.
Warum haben wir aber ein Kommando genutzt, das zur Änderung des Zweiges dient? Die Änderung des Zweiges ist zwar die häufigste Situation für die Anwendung des Kommandos Checkout, das aber ist ein Sonderfall. Im Allgemeinen dient dieses Kommando dazu, die Dateien im Arbeitsverzeichnis mit deren Zustand in der gegebenen Revision zu synchronisieren.
Verwendung eines Abschnitts der Datei
Es kann vorkommen, dass wir in einer Datei sehr viele Änderungen eingeführt haben, die miteinander thematisch nicht zusammenhängen (was das im Kontext einer Datei auch bedeuten mag ;)), oder dass wir einfach ganz schnell ein Commit anlegen möchten, das ausschließlich einen Teil der Änderungen beinhalten wird und den Rest möchten wir noch verschieben. Die einfachste Lösung hier ist der Schalter -p des Kommandos add:
$ git add -p katalog/plik
Mit Git können wir die Codeblocks, die in der nächsten Revision angewendet werden, Schritt für Schritt akzeptieren. Das Resultat kann mit folgendem Kommando geprüft werden:
$ git status
Im Endeffekt erhalten wir zwei Dateiversionen mit unterschiedlichen Änderungen – die Version mit den von uns akzeptierten Blocks befindet sich in staging area, die sonstigen Blocks bleiben in der modifizierten Datei im Arbeitsverzeichnis.
Historie des Zustands des Zweiges
Ich habe schon früher angedeutet, dass wir auf die Revision auch durch den früheren Zustand der Branches (HEAD oder Zweige) verweisen können. Achtung: die Historie der Änderungen des Branch-Zustands ist mit der Historie der Änderungen des Projektes, die mithilfe der Kette der Revisionen dargestellt wird, nicht identisch. Um das Problem zu veranschaulichen, stellen wir uns vor, dass der Zweig feature mit dem Zweig master integriert wird, wodurch Master drei Commits „gewonnen hat” – sein Zustand aber hat sich nur einmal geändert. Um die Historie der Änderungen des Zustands des gegebenen Zweiges wiederzugeben (mit anderen Worten, Revisionen, auf die sich während der Arbeit der repräsentative Branch verwies), bedienen wir uns des Kommandos reflog:
$ git reflog master
Analog bekommen wir die Historie der anderen Zweige. Das Kommando reflog ohne Parameter zeigt die Historie der Änderungen des Branches HEAD. Auf die Zustände der Zweige können wir auch durch folgende Referenzen verweisen: master@{1}, master@{2}, feature@{4}, HEAD@{10}, sowie durch Zeitbezeichnungen: master@{yesterday} oder master@{2 months ago}. Das Kommando:
$ git show master@{"2 months ago"}:katalog/plik
ermöglicht zum Beispiel, die frühere Version einer einzelnen Datei durchzusehen.
In der Praxis wird diese Art des Verweises auf die Revision meistens zwecks Wiederherstellung des Zustands des Zweiges nach der Durchführung eines misslungenen Kommandos, das seine Historie ändert, verwendet (z.B. merge oder rebase). Dazu ist das Kommando:
$ git reset --hard master@{1}
ausreichend, um den Zustand des Zweiges vor der misslungenen Änderung wiederherzustellen.
Detached HEAD
Nehmen wir zum Schluss an, dass wir die Funktionsweise des Projektes schnell testen oder den gesamten Code der gegebenen Revision sehen möchten. Dafür können wir uns dem Kommando checkout bedienen, z.B.:
$ git checkout fed82d9
$ git checkout master{yesterday}
$ git checkout origin/master
Diese Kommandos verschieben uns in den Modus „detached HEAD”, was bedeutet, dass wir uns aktuell in keinem Zweig befinden, aber dass das Arbeitsverzeichnis mit der durch den Parameter bezeichneten Revision synchronisiert wurde.
Literaturnachweis:
Mehr über die Mechanismen der Datenspeicherung in Git, Arbeitsmethoden mit Zweigen, Möglichkeiten des Verweises auf die Revisionen sowie der Verwendung des rebase-Kommandos können Sie im Handbuch und folgender Dokumentation finden:

.png)


